在存在多个数据源的情况下,经常会使用到IBM SPSS Statistics的数据合并功能,对多个数据源的数据进行合并。 比如在收集地区数据时,需要不同地区的人员分开收集,而在数据汇总的阶......
SPSS数据合并_SPSS如何进行变量合并
SPSS教程
2023-01-15
在存在多个数据源的情况下,经常会使用到IBM SPSS Statistics的数据合并功能,对多个数据源的数据进行合并。
比如在收集地区数据时,需要不同地区的人员分开收集,而在数据汇总的阶段,就需要使用到数据合并的功能将这些不同来源的数据合并汇总。本节,我们将会重点学习变量的合并。
一、打开需合并的数据
变量合并的作用是将不同数据文件中,相同个案的不同变量数据进行合并。比如数据A包含了年龄、性别等数据,而数据B包含了地区、收入等数据,而这些数据都是来自同一批个案,就可以通过变量合并数据。
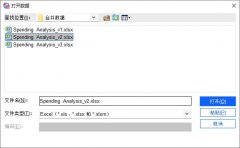
首先,在SPSS中分别打开两个需要合并的数据文件。

图1:打开数据
如图2所示,可以看到,两个数据文件中存在着账号、性别、客单价三个相同变量,以及Area、地区、来源、点击页面数四个不同变量,其中地区与Area实际为同一个变量,但命名方式不同。

图2:对比变量差异
二、使用变量合并功能
接着,如图3所示,依次打开数据-合并文件-添加变量,针对数据文件的异同点进行变量合并。
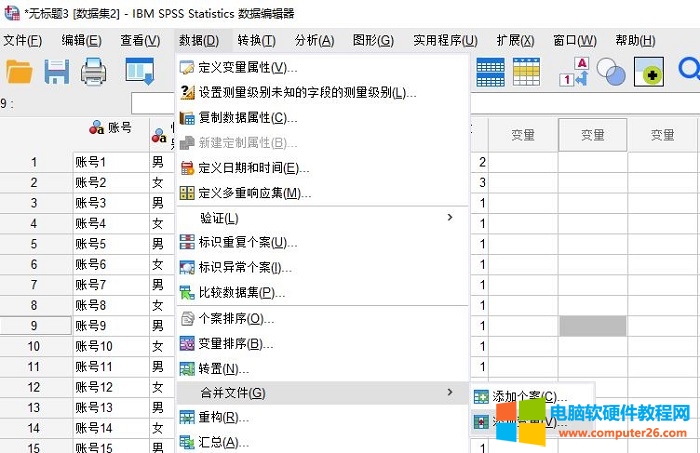
图3:变量合并功能
由于当前打开的是数据集2,因此最终的数据会合并到数据集2中。如图4所示,以数据集2为基础,与之前已打开的数据集3进行合并。
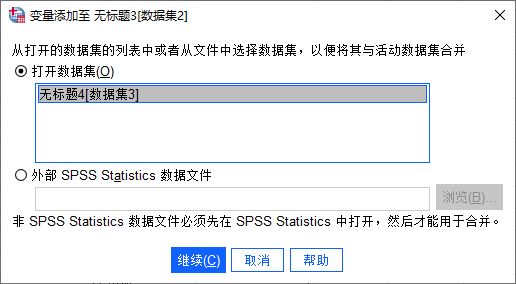
图4:指定合并的数据文件
接着,如图5所示,打开变量选项卡,进行变量合并的设置。
其中,变量括号中含+的是数据集2中不包含的变量,而含*的是数据集2中包含的变量。设置的变量含义如下:
排除的变量,即两个数据文件中存在差异的,但在合并数据过程中需要剔除的变量。
包含的变量,即两个数据文件中存在差异的,但在合并数据过程中需要保留的变量。
键变量,即两个数据文件同时包含的变量。
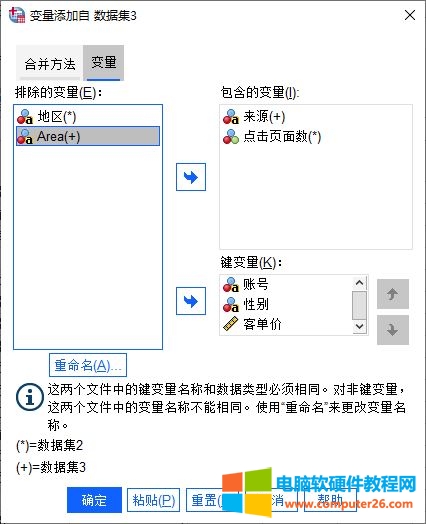
图5:设置变量的合并方式
由于变量“地区”与“Area”实际为同一变量,可将其中一个添加为“包含的变量”,另外,还可以通过重命名的方法,将“Area”重命名为“地区”。
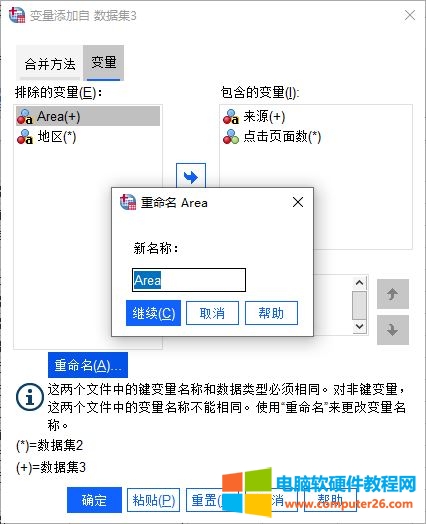
图6:重命名变量
如图6所示,可以看到“Area”已重命名为“地区”,将其添加为“包含的变量”。
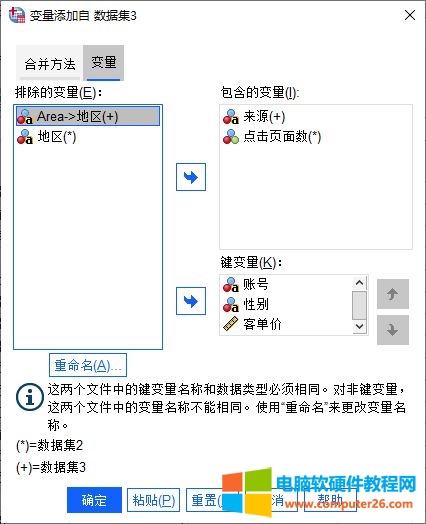
图7:完成变量的重命名
如图7所示,在包含的变量中,“Area”变量已经重命名为“地区”变量。当然,我们也可以直接使用数据集2中包含的“地区”变量。

图8:添加重命名后的变量
完成以上操作后,如图8所示,可以看到,变量已经合并完成。后续,可对数据作进一步的整理,如排序等。
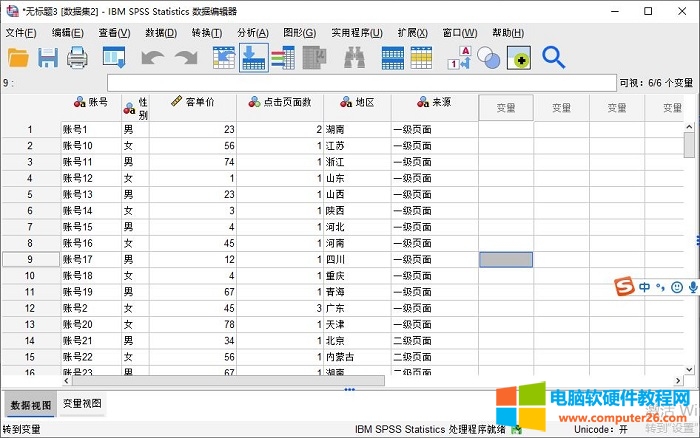
图9:完成变量的合并
相关文章
- 详细阅读
- 详细阅读
-
SPSS数据文件的建立_SPSS创建与导入方法演示详细阅读
数据分析指的是使用各种统计方法,如随机抽样、普查等方式收集大量的数据,并对其执行统计分析的过程,因此,数据是执行分析的基础。 那么,该如何将收集到的数据导入到IBM S......
2023-01-15 202 SPSS数据文件的建立 SPSS创建与导入方法
