我们在用 IBM SPSS 进行数据分析的时候,经常会遇见这样一种情形,想把不符合自己分析要求的数据全部筛掉。我们把这些要筛掉的数据叫作无效数据,无效数据不筛选掉不但会降低分析......
2023-10-08 1278 SPSS筛选无效数据
IBM SPSS Statistics的定制表功能,可进行多个变量的交叉分析,适合用于多维度的数据洞察。其功能与Excel表的透视表功能相似,但比Excel更实用的是,SPSS定制表还可进行均值、标准差、中位数等统计量的描述。
接下来,我们通过实例详细地演示一下定制表的使用方法。
一、数据准备
本文使用的是一组既包含销售量、销售额、客流量等定量变量,又包含店铺类型、星级等定性变量的数据,便于后续的交叉分析。
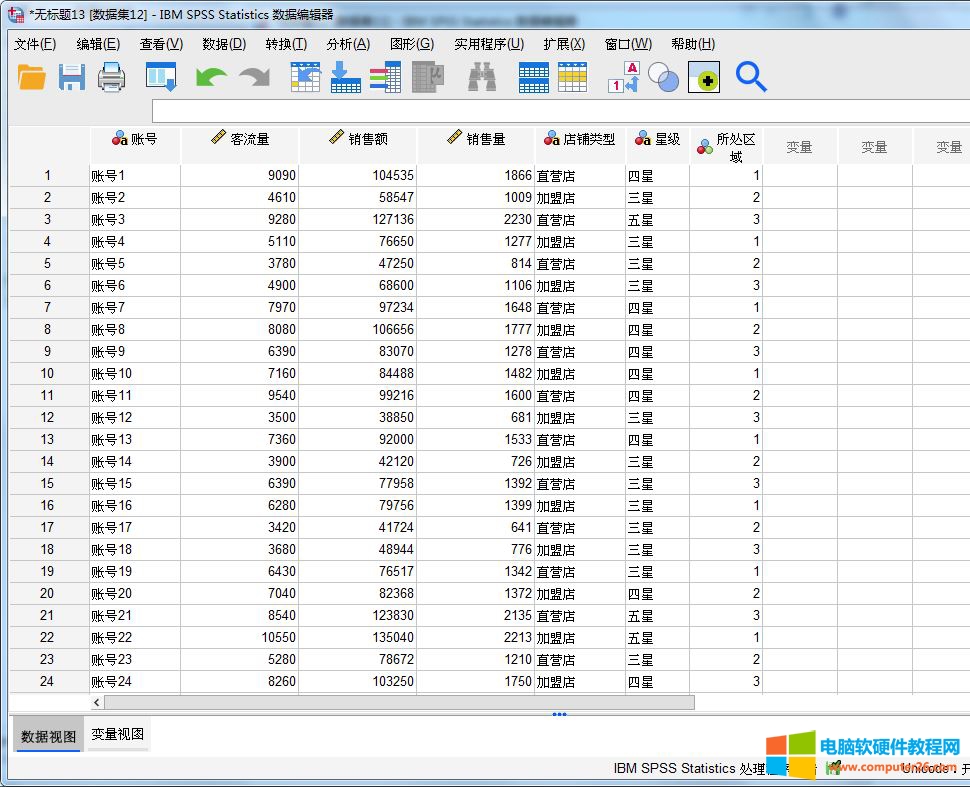 图1:销售额与客流量数据
图1:销售额与客流量数据
二、定制表分析
1、定义变量属性
如图2所示,依次单击分析-表-定制表选项,开启定制表功能。
图2:定制表
在正式使用定制表功能前,SPSS会进行分类变量的定义值询问。由于本例中的“所处区域”实际上属于分类变量(进行了变量的赋值),需单击“定义变量属性”,进一步定义其标签。
图3:定义变量属性
如图4所示,将“所处区域”添加到要扫描的变量。
图4:扫描的变量
扫描完成后,如图5所示,在值标签网格中,可为“所处区域”变量对应的数值型值添加标签,比如值“1”对应的值标签为“A区”,可将“A区”填写到值1对应的标签列中。
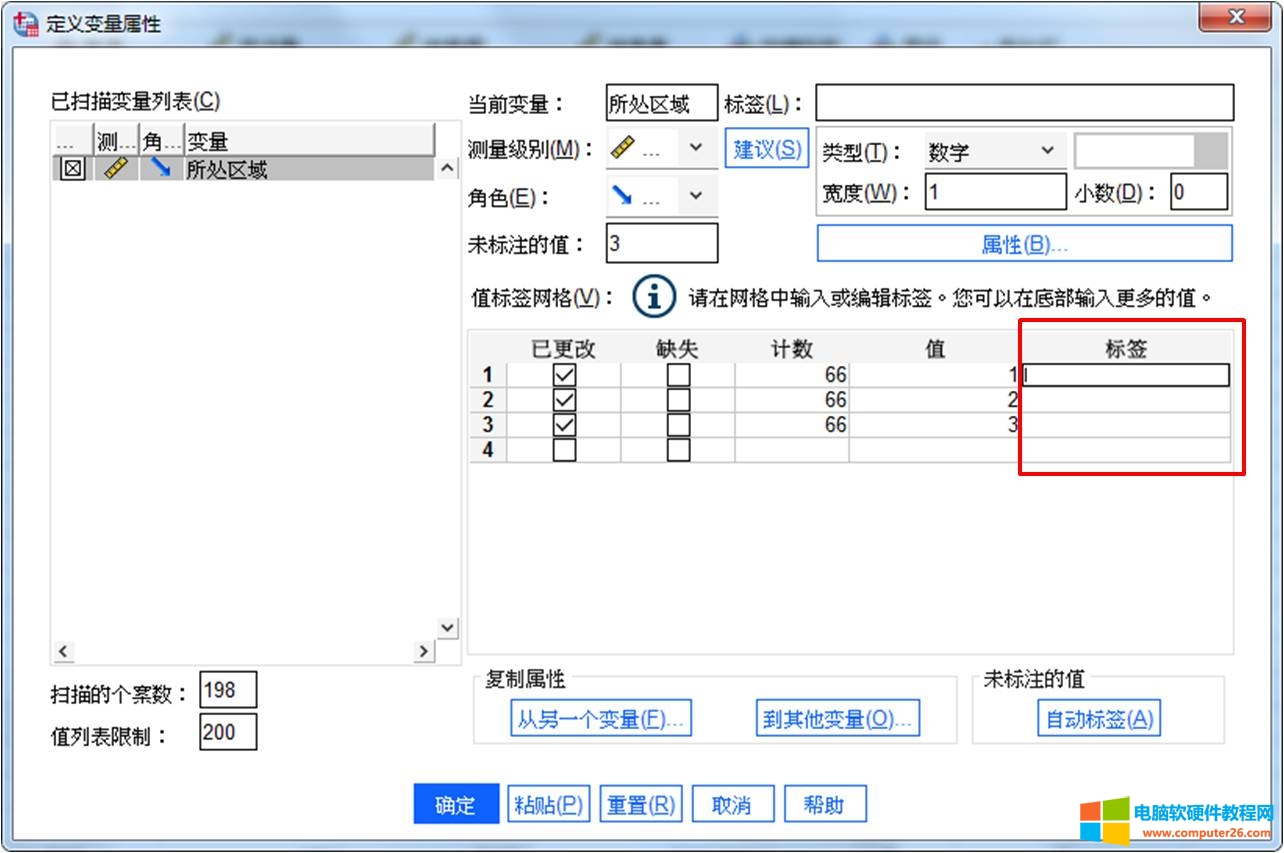 图5:设置数据值标签
图5:设置数据值标签
值标签的填写效果如图6所示,同时,将“所处区域”变量更改为有序测量。
完成以上调整后,“所处区域”变量才能与其他定量变量进行交叉分析。

图6:定义测量级别
2、定制表设置
完成变量属性的调整后,打开定制表设置界面。
如图7所示,定制表包含了表、标题、检验统计与选项的设置。
图7:定制表
第一步,进行表的设置,如图8所示,将销售额添加为列,所处区域添加为行。
第二步,打开摘要统计,进行统计量的设置。
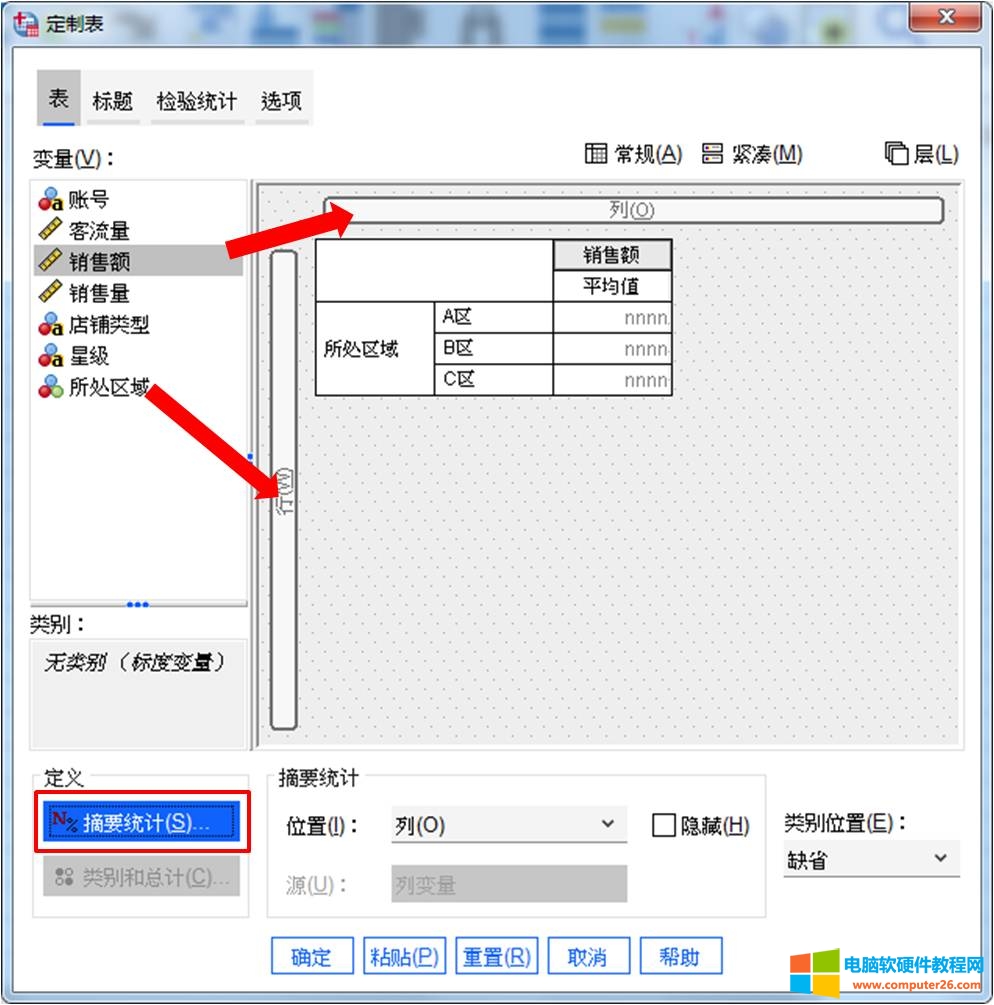 图8:设置变量
图8:设置变量
根据统计的需要,选择合适的统计量。本例选择了平均值、计数、最大值与行N%的统计量,以得到不同区域店铺的销售均值、最大值的数据。
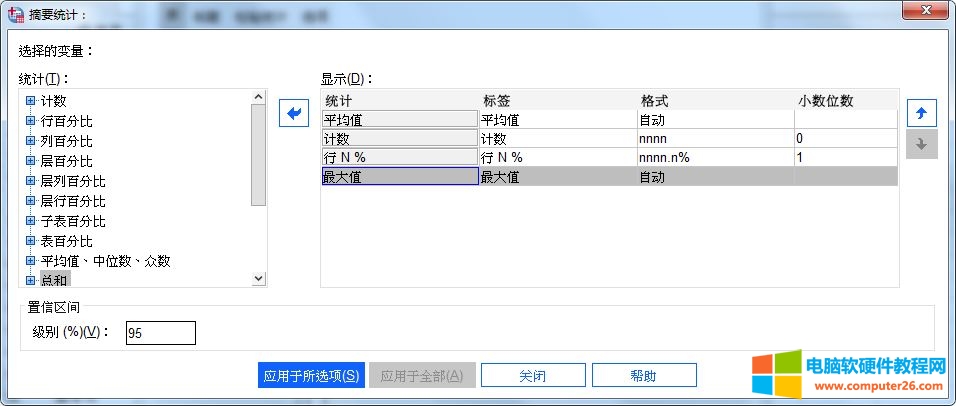 图9:统计量设置
图9:统计量设置
根据以上设置,得到如图10所示的运算结果。
从结果得出,C区店铺均值最高,但A区店铺的最大值更大。
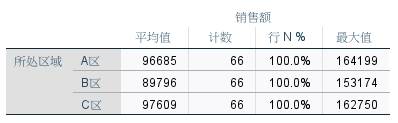
图10:所在区域与销售额交叉分析
除了进行简单的两变量交叉分析外,还可添加多个变量进行多变量的交叉分析。比如,如图11所示,将所处区域、店铺类型、星级都添加到行。
 图11:多变量交叉
图11:多变量交叉
即可分析不同区域、不同店铺类型、不同星级店铺的销售平均值。
比如,A区直营店铺,特别是五星级的直营店铺销售均值更高。
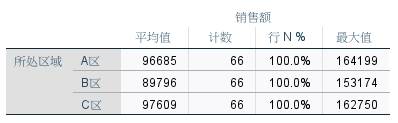
图10:多变量交叉分析结果
三、小结
综上所述,如果要进行多变量数据的交叉分析,那么IBM SPSS Statistics的定制表是一个十分好的选择。其直观的界面、丰富的统计量,可轻松地进行多变量的spss交叉分析,并可通过均值、中位数等统计量的比较,获得更有价值的数据洞察。
相关文章
我们在用 IBM SPSS 进行数据分析的时候,经常会遇见这样一种情形,想把不符合自己分析要求的数据全部筛掉。我们把这些要筛掉的数据叫作无效数据,无效数据不筛选掉不但会降低分析......
2023-10-08 1278 SPSS筛选无效数据
在使用IBM SPSS Statistics进行数据分析时,我们需要根据数据类型选择合适的检验方法,卡方检验就是一种较为常用的数据检验手段。 为此小编整理了一份 SPSS卡方检验 的基础教程供大家......
2023-11-17 255 SPSS卡方检验教程
假设有这样一则报道,某高校学生平均每天学习时间2.5小时。调查该高校16个学生的学习时间,能否验证报道的正确性。学过一点数学的人大概率会说,样本量不足,偶然性很大不能够......
2023-10-08 324 SPSS进行T检验
IBM SPSS Statistics的比较平均值分析法属于参数型的检验法,是以已知总体分布的前提下,检验样本数据与总体数据的差异,其中包含了平均值、单样本T检验、独立样本T检验、配对样本......
2023-01-15 246 SPSS单样本 SPSS独立样本 SPSS配对样本T检验