IBM SPSS Statistics的数据重构功能,也被称为数据重组,包含了将选定变量重组为个案、将选定个案重组为变量与变换所有数据(即数据转置)的功能。 为什么要进行数据重组?这是因为......
SPSS数据重构_SPSS如何将选定个案重组为变量
SPSS教程
2023-01-15
IBM SPSS Statistics的数据重构功能,也被称为数据重组,包含了将选定变量重组为个案、将选定个案重组为变量与变换所有数据(即数据转置)的功能。
本文中,会进行“将选定个案重组为变量”的功能讲解。当我们要进行分组变量的分析时,就需要将个案组数据转换为变量组数据,比如一般线性模型分析中的单变量、多变量和方差成分。
一、打开数据文件
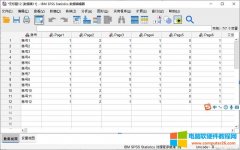
首先,如图1所示,打开个案组类型的数据。当前数据展示了个案在不同页面中的浏览次数,需要将“页面编号”重组为新变量。
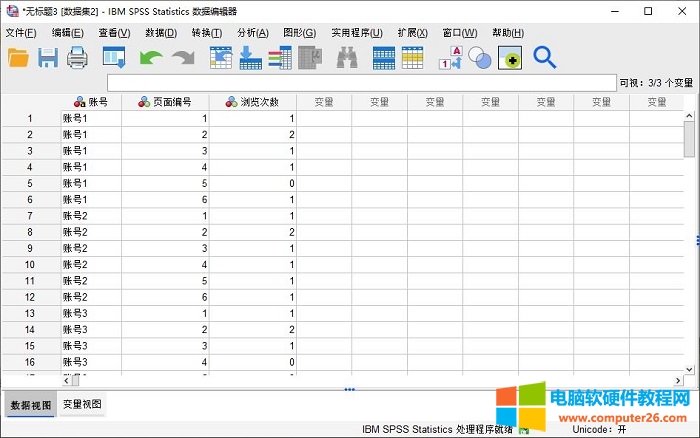
图1:打开数据文件
二、使用数据重构功能
如图2所示,打开数据菜单中的重构数据功能。
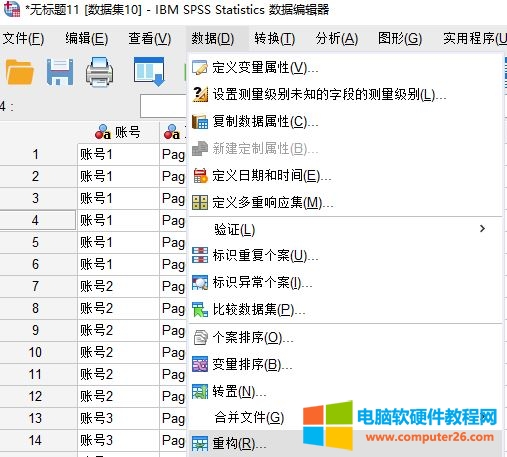
图2:数据重构功能
三、选择将个案重构为变量
如图3所示,在打开的重构数据向导中,可以选取数据重构的方法。我们选择“将选定个案重构为变量”选项。
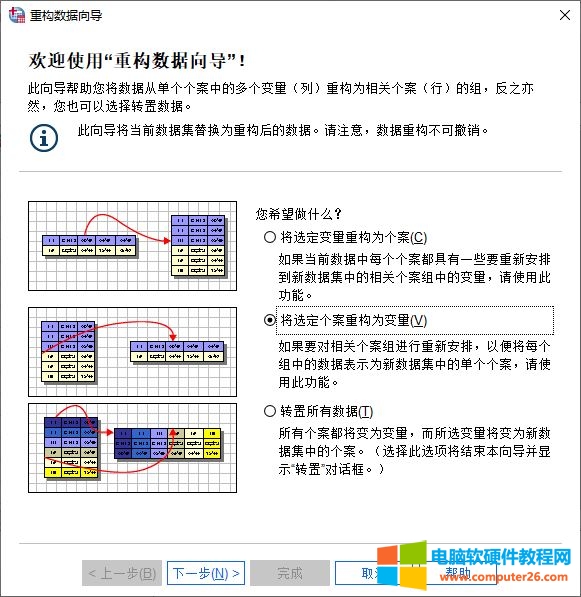
图3:重构数据向导
接着,我们需要进行比较关键的一步—选择变量。其中的变量含义如下:
1.标识变量,即用来识别个案的变量,比如本例中的“账号”变量,可用于识别个案。
2.索引变量,当前数据中用于创建新列的的变量。当变量添加为索引变量后,系统会将该变量中的变量值重组为新列变量。比如本例中的“页面编号”变量。
3.当前文件中的变量,不发生变更的变量,该变量的数据可能会因重构而改变。
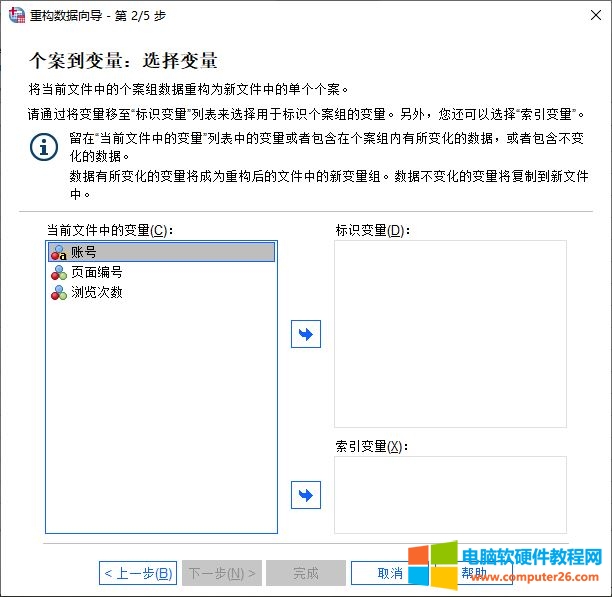
图4:选择变量
根据当前数据的重构的目的,即将“账号”的个案组数据重构为单个个案,如图5所示,需将“账号”设置为标识变量,将“页面编号”设置为索引变量,保持“浏览次数”为当前文件中的变量。
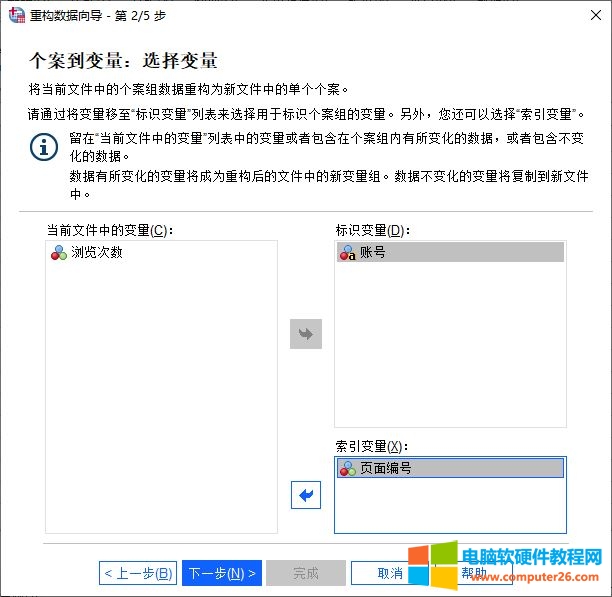
图5:设置变量
接着,设置数据的排序方式,可按照标识变量与索引变量进行排序,也可选择按照当前排序状态排序。
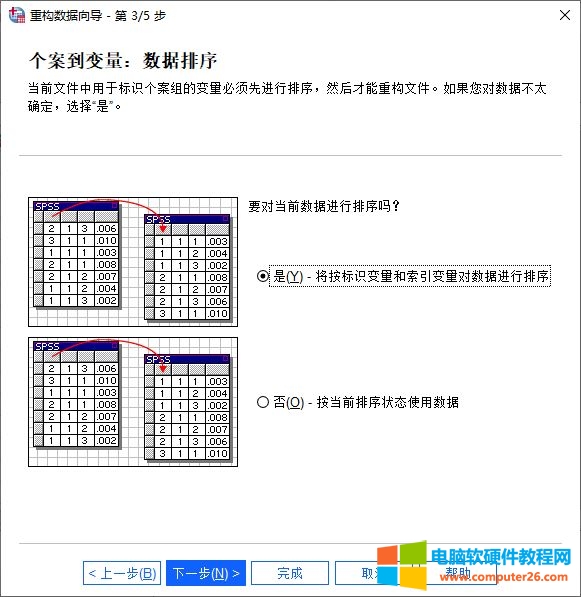
图6:排序选项
最后,对应用于重构后的数据文件选项进行设置:
1.设置新变量组的顺序,可按原始变量分组(先排序变量1,再排序变量2,如w1 w2 w3,h1 h2 h3)或按索引变量分组(所有变量放在一起排序,如w1 h1,w2 h2,)
2.添加个案计数变量
3.创建指示符变量,可使用索引变量在新的数据文件中创建指示符变量,它为索引变量的每个唯一值创建一个新变量。
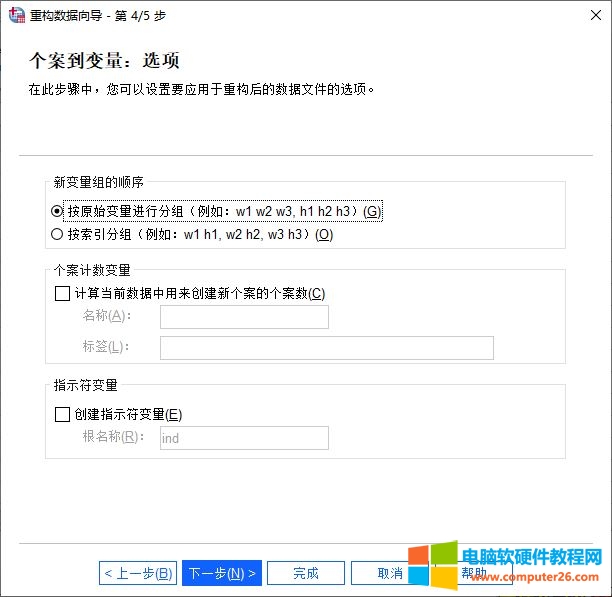
图7:重构后数据文件的选项
完成数据重构设置后,我们可以选择立即重构数据,或保存、修改算法后再重构数据。

图8:保存算法或立即重构
完成数据重后,如图8所示,数据展现了在不同个案下不同索引变量的浏览次数。
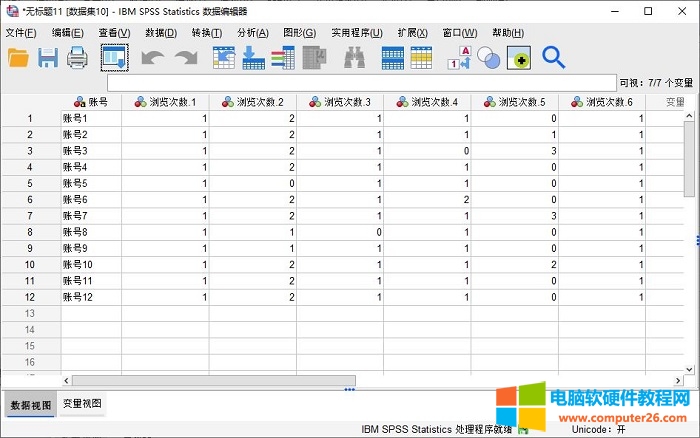
图9:完成数据的重构
相关文章
- 详细阅读
-
SPSS数据文件的建立_SPSS创建与导入方法演示详细阅读
数据分析指的是使用各种统计方法,如随机抽样、普查等方式收集大量的数据,并对其执行统计分析的过程,因此,数据是执行分析的基础。 那么,该如何将收集到的数据导入到IBM S......
2023-01-15 203 SPSS数据文件的建立 SPSS创建与导入方法
- 详细阅读
-
SPSS数据重构_SPSS如何将选定个案重组为变量详细阅读
IBM SPSS Statistics的数据重构功能,也被称为数据重组,包含了将选定变量重组为个案、将选定个案重组为变量与变换所有数据(即数据转置)的功能。 本文中,会进行将选定个案重组为......
2023-01-15 201 SPSS数据重构 SPSS将选定个案重组为变量
-
SPSS数据重构_SPSS转置所有数据详细阅读
IBM SPSS Statistics的数据重构功能,也被称为数据重组,包含了将选定变量重组为个案、将选定个案重组为变量与变换所有数据(即数据转置)的功能。 本文中,会进行数据转置的功能讲......
2023-01-15 200 SPSS数据重构 SPSS转置所有数据
